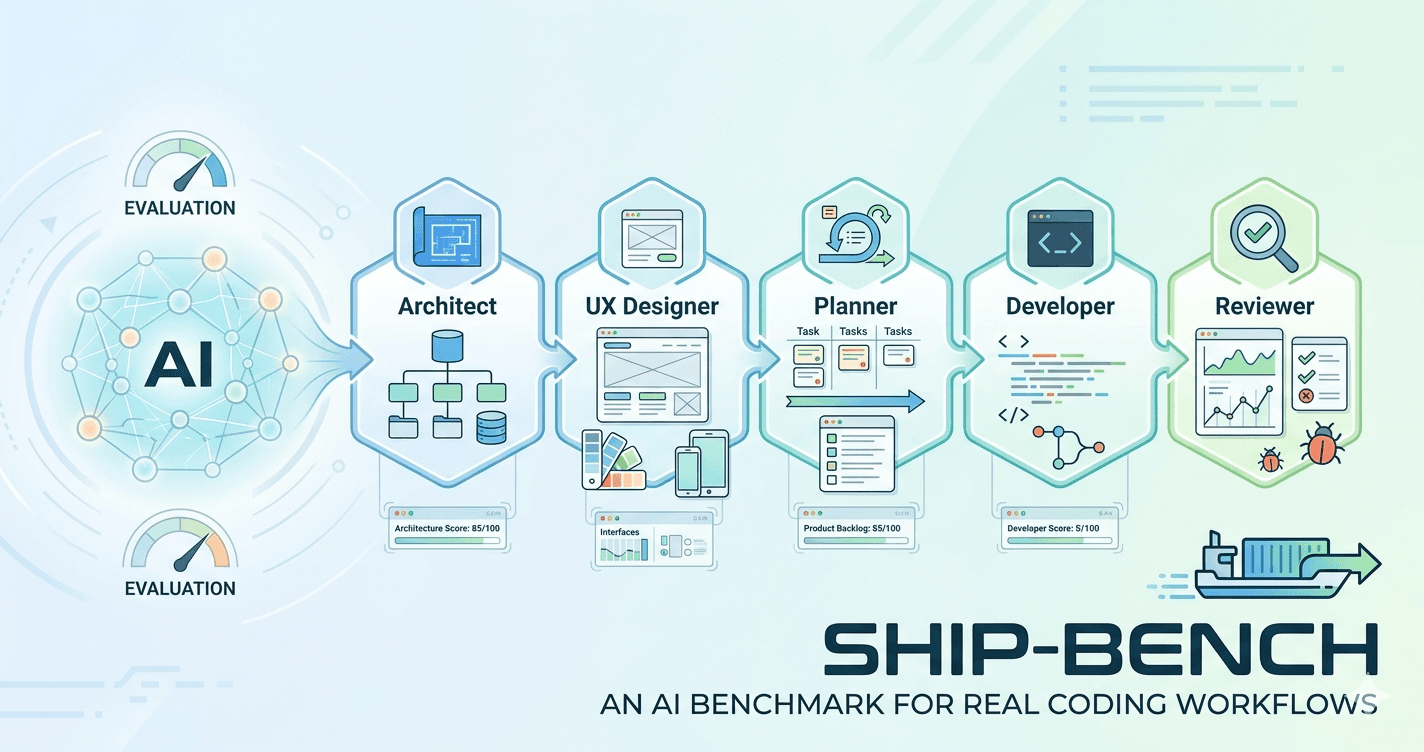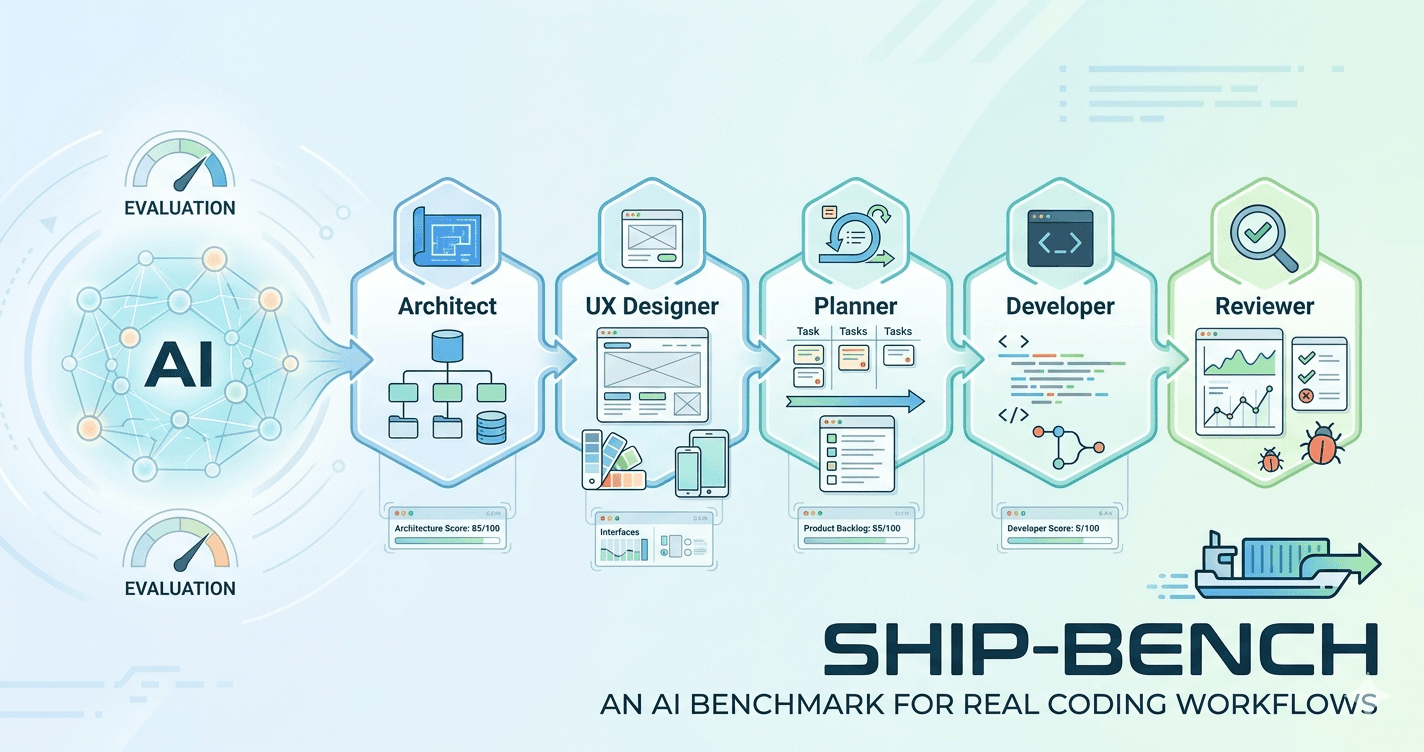
An AI Benchmark That Tests Real Coding Workflows
Developers face a real choice: pick a coding model or agent based on synthetic benchmarks that look great but do not predict actual project work. The problem is no longer whether models can score well
Apr 19, 20268 min read41